--- 읽기전 당부사항 ---
나름 자료를 찾고 이해해서 올린 자료입니다. 혹시나 틀리게 있다면 뭐 이런게 다있어 하고
끝내지 마시고 잘못된 정보 때문에 다른 선의에 피해자가 없게 쪽지나 메일 댓글 등을
이용해서 알려주세요 (--)(__)(--) 굽신~굽신~
글쓰게된 배경 및 푸념~
“이것 하나만 읽어 보시면 IT쪽 일을 하시는 분이라면 감을 잡을 수 있다고 생각합니다.” 프로그램 경력은 많지만 UNICODE에 대해 자세히 찾아보고 이해하는데 완벽하다는 아니지만 아 이거구나 이해하는데 몇 시간 걸리고 이해만 하고 끝내자니 뭔가 아쉽고 저와 같이 시간낭비 하시는 분이 없기를 바라는 마음으로 블로그에 내용을 정리해서 올리자는 생각에 일단 워드을 켜고 제목을 쓰니 왠지 막막하더군요 -_-;; 그래도 주절주절 쓰다 보니 자료가 왠지 부족하고 용어설명도 두리뭉실하게 되어 있어 혼돈이 되기도 하고 그래서 하나씩 이해할 수 있는 자료까지 수집하는 대까지 꼬박 20시간이 걸리더군요 -_-;; 거짓말 안하고 정리한걸 주욱 보니 왜 20시간이나 걸렸을까 내가 이해력이 딸리구나 라고 생각했습니다. 그렇지 않고서야 이렇게 오래 걸릴리 없지요 아~~~ 이자괴감 ㅜㅜ 아훅… 이걸 다시 정리하려면 몇시간 더 걸리겠져 뭐 그래도 왠지 뿌듯하네요. 그리고 누군가 꼭!!! 제~에~발 도움이 되었으면 좋겠습니다. |
유니코드 와 유니코드 인코딩 차이
UTF-8/UTF-16/UTF-32/EUC-KR은 유니코드가 아니고 유니코드를 인코딩하는 방식을 말합니다. 유니코드 와 유니코드 인코딩을 저를 포함해서 혼돈하시는 분들이 많이 있는거 같더군요 물론 알지만 다들 그렇게 명하니까 그렇게 말씀하시는 분도 있지만요 어떻게 명하던 확실한 차이를 알아야 한다고 생각합니다. |
유니코드(UNICODE)
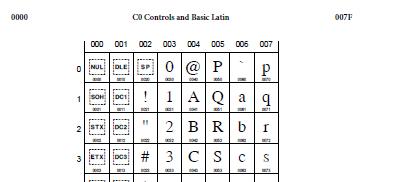
유니코드(UNICODE)는 컴퓨터에서 세계 각국의 언어를 통일된 방법으로 표현할 수 있게 제안된 국제적인 문자 코드 규약입니다. 간단하게 말해서 세계 모든 문자를 0번부터 주욱 번호를 정해서 표를 만든 거라 생각하시면 됩니다.
0000부터~ 시작합니다.
한글은 AC00부터 시작하며 AC00는 "가" 입니다.
유니코드표는 아래 사이트 가시면 모두 볼수 있습니다.
http://rudhar.com/lingtics/uniclnks.htm |
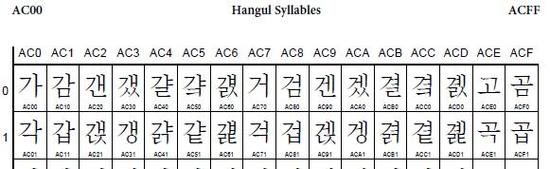
유니코드는 2Byte다?
절대 아닙니다. 저도 처음에 유니코드는 2BYTE고 65536면 세상모든 문자를 표현하고도 남지 라고 생각했습니다. 그런데 이번에 알게 되었지요 예전에는 2BYTE였는지는 모르지만 시간이 흐르고 UNICODE버전이 올라가면서 많은 문자가 추가 되었습니다. 보시면 알겠지만 별 이상한 특수문자도 많이 있습니다. 아래 주소에 가시면 UNICODE영역에 대해 알수 있습니다. http://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C 그럼 도체 뭔 문자가 들어가 있는지 궁굼해서 보기 쉽게 한눈에 볼 수 있는 사이트를 찾아 봤는데 이거 찾는데도 30분이 넘더군요 아래 주소에 가시면 유니코드 표를 볼 수 있습니다. 영어 울렁증 있으신 분들 놀라지 마시고요 코드표 클릭해서 코드표만 보시면 되고요 나머지 내용은 한글로 잘 번역되어 있는 사이트 많이 있습니다. ^^ http://rudhar.com/lingtics/uniclnks.htm |
유니코드 인코딩 종류?
흔히 가장 많이 사용하는 것들은 UTF-8/UTF-16/UTF-32/UCS2/UCS4 등 더 있지만 가장 많이 사용한다고 생각되는 것만 나열 했습니다. (솔직히 더 찾아 보기도 싫고 방법이 틀리거나 탄생 배경이 틀릴 뿐이지 거기서 거깁니다.)
|
유니코드 인코딩은 왜하는가?
유니코드에 대해서 알아보면서 개인적으로 결론입니다. 맞을 수도 있고 틀릴 수도 있습니다.
“한마디로 정의하자면 용량을 줄이기 위함이지요 그 종류가 어려가지가 있는 것이고요” 유니코드는 여기까지만이다 하고 끝나는게 아니라 계속 추가 됩니다. 새로운 문자가 생기 있고 아직 추가되지 않은 문자도 많이 있을 거니까요? 현재는 3바이트? 있으면 되지만 앞으로는 오바해서 10BYTE가 될 수도 있습니다. 그럼 한문자를 표현하기 위해서 10BYTE 씩 할당하자니 공간 낭비고 왜 공간 낭비냐 a(61)를 표현하기 위해 00 00 00 00 00 00 00 00 00 61 이렇게 넘처나는 00을 보세요 ㅋㅋ 잘 쓰지도 않는 문자들 때문에 저 공간을 할당해야 한다는 것이 낭비겠지요? ^^ 그래서 나온 것이 인코딩 입니다. 인코딩이라고 해서 특별한게 있는게 아니고요 필요한 문자 및 잘 사용하는 문자를 모와서 코드표를 만들고 그걸 기준으로 변환 하는 것이지요 |
EUC-KR, KSC5601, MS949(CP949)는 같다?
결론은 먼저 말하자면 틀립니다. 웹프로그램할 때 가장 많이 사용하고 볼 수 있습니다. 저도 처음에 같은건가 해서 검색을 했는데 어떤분이 저랑 같은 생각을 했는지 질문은 했더라고요 답변을 자바를 기준으로 해서 답변을 했는데 옛날에는 KSC5601이라고 이름을 사용했고 자바가 버전 업이 되면서 EUC-KR로 이름이 변경 되었다라고 설명을 했더라고요 전 틀렸다고 생각합니다. 인코딩 규약이름을 JAVA가 마음대로 할 수는 없는 것이지요. 옛날에는 KSC5601를 사용했는데 지금은 EUC-KR를 사용한다면 모를까요 ^^ 아래 인코딩 종류별로 설명 하겠지만 간단하게 설명하자면 이렇습니다. EUC-KR : KSC5601 + KSC5603 EUC-KR 을 확장한 것이 CP949입니다. KSC5601 < EUC-KR < CP949 이런 관계입니다
|
중간정리
- UTF-8/UTF-16/UTF-32/UCS2/UCS4/EUC-KR/CP949는 유니코드 인코딩 종류이다. - KSC5601,EUC-KR,CP949는 다른 것이다. - UTF-8은 1~4BYTE 까지 가변적으로 인코딩 한다.(영문 :1BYTE 한글 : 3BYTE) - UTF-16은 2~4BYTE 까지 가변적으로 인코딩 한다.(영문:2BYTE 한글 : 2BYTE) - UTF-32은 4BYTE로 고정으로 인코딩 한다. 아래 더 자세한 내용을 있지만 여기까지만 알아도 별문제 없다고 생각합니다. 차이점만 요약해서 알아도 프로그램하는데 문제는 없으니까요 뭐 여기까지 내용을 모른다고 해서 프로그램을 못하는것도 아니지만요 ^^
|
유니코드 인코딩 종류 설명
아래 내용은 설명이 잘되어 있는 사이트에서 가지고 왔습니다.
참조사이트 : http://misskor.com/173
UTF-8
문자에 따라 1 ~ 4 BYTE로 가변적으로 표현합니다. 자세한 내용 : http://ko.wikipedia.org/wiki/UTF-8 |
UTF-16
문자에 따라 2 BYTE 혹은 4 BYTE 로 표현합니다. UTF-16은 모든 영역의 유니코드를 표현할 수 있는 가변길이 유니코드 인코딩이다. 기본언어판(BMP, U+0000~U+ffff) 영역은 한개의 16-bit 워드로 인코딩되고, 다른 언어판(U+10000 이상) 영역의 문자는 두개의 16-bit 대행 코드 쌍(surrogate pair)로 인코딩된다 자세한 내용 : http://ko.wikipedia.org/wiki/UTF-16
|
UTF-32
4 BYTE 로 각 문자를 표현합니다. |
UCS-2(Universal Character Set 2(octets))
하나의 문자를 2 BYTE로 표현합니다. 65536까지 코드표는 UTF-16과 똑같다 다만 그 이상에 문자를 표현할 수 없다는 점만 틀리다 UCS-2는 UTF-16의 선배격인 인코딩 방식이다. UCS-2는 대행 코드쌍을 지원하지 않는 걸 빼고는 UTF-16과 똑같다. 따라서, 기본언어판(BMP, U+0000~U+ffff)만 인코딩 할 수 있다. 결론적으로 16-bit single word 고정길이 인코딩 방식이다. |
UCS-4 (Universal Character Set 4(octets))
하나의 문자를 4 BYTE 로 표현합니다. |
EUC-KR
euc계열은 유닉스계열 코드페이지이고 완성형 코드이다 EUC-KR 완성형 코드라서 "뚫훍뚤훍" 같은 글자를 표현 할 수 없습니다. 조합형 코드라면 모든 것을 표현할 수 있지만, 그럴 수 없습니다. Bell Laboratories에서 유닉스 상에서 영문자 이외의 문자를 지원하기 위해 제안한 확장 유닉스 코드(Extend UNIX Code)중 한글 인코딩 방식 영문은 KSC5636로 처리하고 한글은KSC5601로 처리 EUC-KR = KSC5601 + KSC5636 자세한 내용 : http://ko.wikipedia.org/wiki/EUC-KR |
MS949(CP949)
이것은 조합형코드는 아니지만, 완성형코드인 EUC-KR에다가 "뚫훍"같은 글자를 포함시켜 더 많은 글자를 표현할 수 있게 되었습니다. 그래서 EUC-KR 보다는 CP949로 하는 것이 더 많은 한글 글자를 표현 할 수 있다는 이야기입니다 코드 페이지 949(CP949), UHC(Unified Hangul Code) 또는 확장 완성형은 한국어 마이크로소프트 윈도에서 사용되는 문자 인코딩이다. 윈도 95에서 처음 소개되었으나, 마이크로소프트에서는 이 인코딩을 기반 문자 집합 이름인 "ks_c_5601-1987"로 사용하고 있다. CP949 인코딩은 EUC-KR의 확장이며, 하위 호환성이 있다. |
KSC5601
한글 완성형 표준(한글 2,350자표현) 한국공업표준 정보처리분야( C )의 5601번 표준안 |
KSC5636
이 문자 집합은 ASCII와 거의 동일하며, 역슬래시(0x5C) 자리에 원화 기호(₩, U+20A9)가 들어 있는 것만 다르다. 그러나 실제로는 대부분의 시스템이 ASCII와의 호환성을 위해 원화 기호를 그냥 역슬래시로 처리하고 있으며, 따라서 실질적으로는 KSC5636과 ASCII를 똑같이 처리해도 별다른 문제가 없다. |
팁
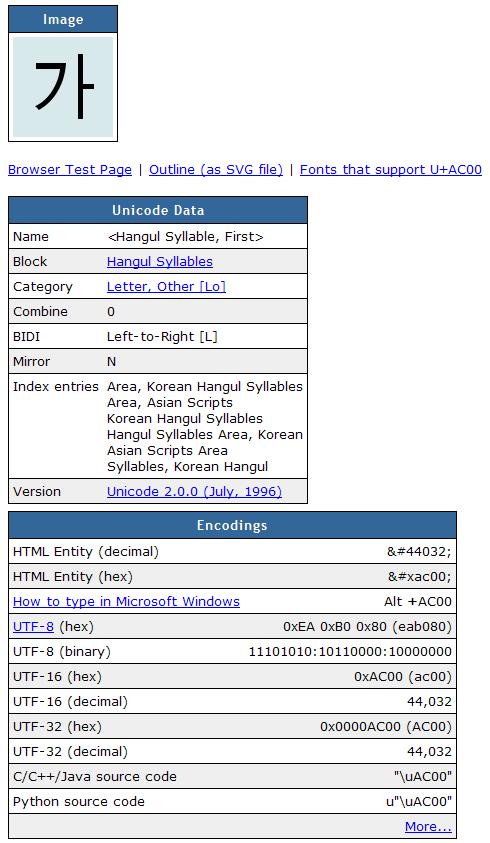
UNICODE표를 보고 html이나 프로그램시 어떻게 변환되고 사용해야 하는지 보는 방법은
http://rudhar.com/lingtics/uniclnks.htm 사이트에서 코드표를 보고 유니코드번호를
아래 URL에 입력하면 볼수 있습니다.
예를 들어 AC00 "가"에 대해 보고 싶다면 아래와 같이 입력하면 됩니다.
http://www.fileformat.info/info/unicode/char/AC00/index.htm
다른걸 보고 싶다면 빨강색 부분에 코드를 수정하시고 엔터를 치시면 됩니다. 그럼 아래 같이 인코딩별로 변환시 값과 활용법을 볼수 있습니다. |
테스트
직접 메모장에서 테스트를 해보겠습니다.
위 내용을 ansi / unsicode(리틀 엔디언) / unicode(빅엔디언) / utf-8로 저장후 어떻게 저장되어 있는지 핵사코드로 보여주는 프로그램(HexEdit.exe)을 이용하여 보겠습니다. |

Ansi
6161 6161 B0A1 6161 이렇게 저장 되어 있습니다. 61나는 a이고 B0A1은 “가” 입니다. B0A1이 “가” 인 인코딩은 cp949입니다. |
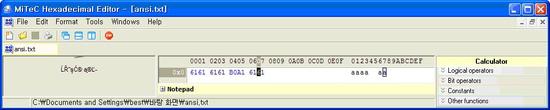
unsicode(리틀 엔디언)
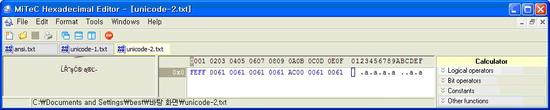
FFFE 6100 6100 6100 00AC 6100 6100 으로 저장 되어 있습니다. 가장 앞에 FFFE는 utf-16으로 저장 되어 있고 리틀엔디언으로 저장 되어 있다는 표시입니다. 그다음 숫자들은 “aaaa가aa”가 인코딩 되어 있는 모습입니다. |
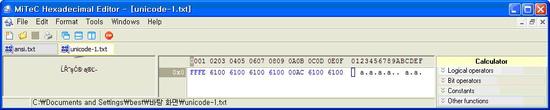
unicode(빅엔디언)
FEFF 0061 0061 0061 AC00 00061 0061 로 저장되어 있는데 전에는 FFFE였는데 FEFF로 변경되어 있는데 FEFF는 utf-16(빅엔디언)으로 인코딩되어 있다는 표시입니다. 그다음 숫자는 “aaaa가aa”가 인코딩 되어 있는 모습입니다. 보시면 알겠지만 리틀엔디언과 빅엔디언은 한바이트식 앞뒤가 뒤바꿔져 있는거 말고는 틀린점이 없습니다. |
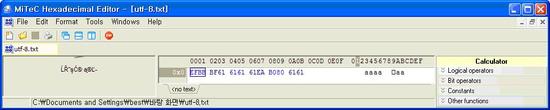
Utf-8
EFBB BF61 6161 61EA B080 6161로 저장되어 있는데요 EFBBBF까지고 utf-8로 인코딩 되어 있는다 내용이고요 61는 a이고요 EAB080이 가를 의미 합니다. Utf-8에서는 한글 한글자를 표현하기 위해서는 3Byte를 사용합니다. 왜 3Byte를 사용하는지에 대해서는 아래 사이트에서 utf-8설계 및 구초를 참조하세요 자세한 내용 : http://ko.wikipedia.org/wiki/UTF-8 |
정리를 다하고 보니 테스트 말고는 여기저기 사이트 내용 정리한거 뿐이 안되는거
같네요 ㅠㅠ 처음 시작할 때는 몬가 대단한걸 하는거 같은 느낌에 들어 뿌듯했는데
ㅋㅋ 역시 글은 쓴다는건 쉬운게 아닌거 같네요 ^^
그래도 최대한 깔끔하고 간단히 정리한다고 했는데 워드로 작업하니 9장이나 나오네요
-_-;; 많이 부족하지만 여기까지 읽어 주셔서 감사하고요 많은 도움이 되었으면 하는 마음이고요 요즘 날씨가 미친거 같던데 몸조심들
[출처] 유니코드(UNICODE) & 엔코딩(Encoding)|작성자 난도
'Development > Common' 카테고리의 다른 글
| JIT 컴파일 (0) | 2012.01.23 |
|---|---|
| 문자 집합(Character Set) 및 문자 인코딩 (0) | 2012.01.19 |
| utf-8 & euc-kr (0) | 2012.01.19 |
| IIOP (0) | 2012.01.16 |
| CORBA (0) | 2012.01.16 |





